

记忆奇点来临!人类三十万年遗忘被哈佛神经科学家终结
刚刚,哈佛医学院神经科学家 Gabriel Kreiman 正式推出了 Engramme,一个要给人类「完美且无限记忆」的 AI 产品。
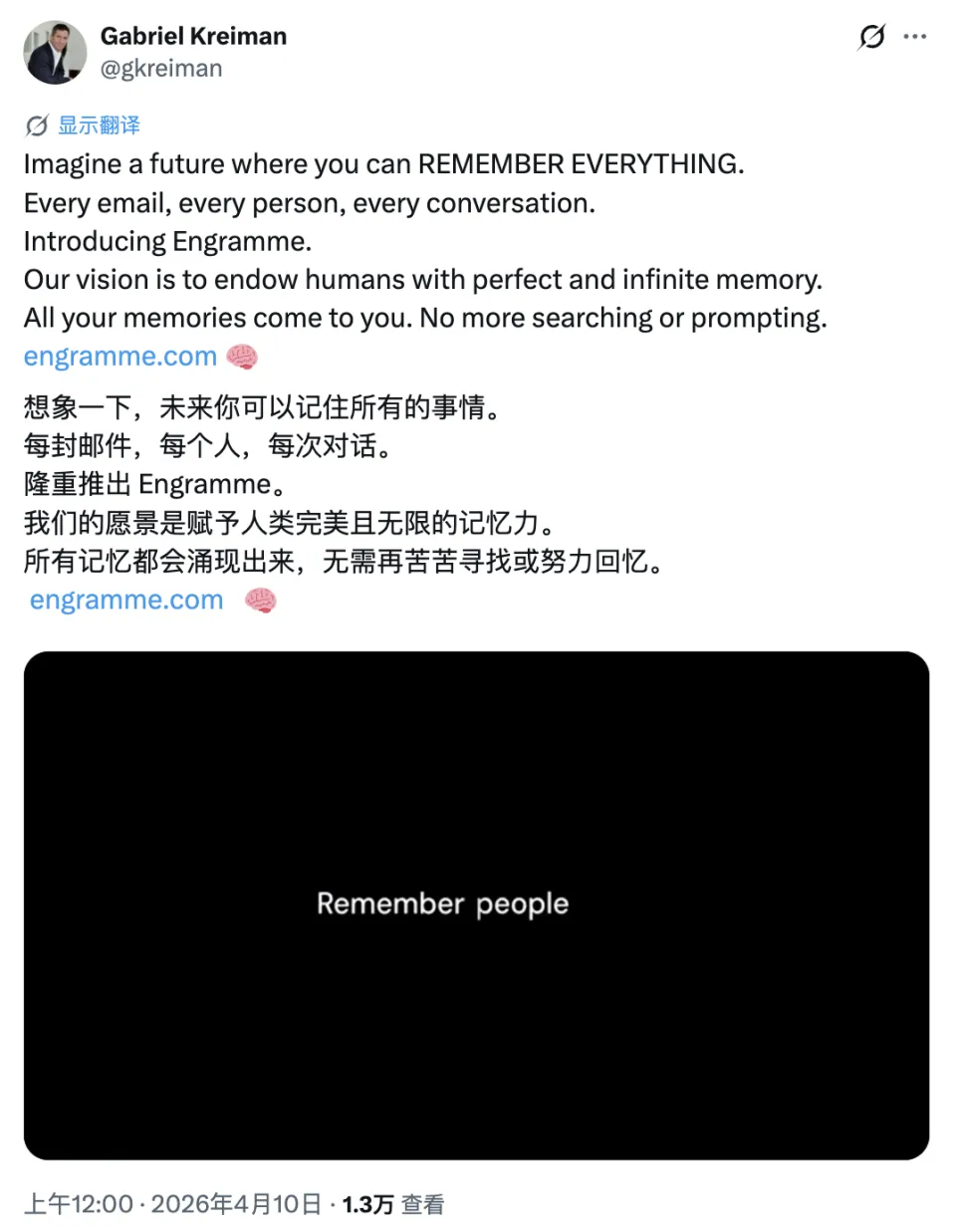
Engramme 的逻辑在于一个核心转变:信息不需要你去找,它会在你需要的时候主动送达。
“ Engramme 的愿景,是赋予人类完美且无限的记忆。你的记忆会自动来找你,不再需要搜索,也不再需要提示。
如果说 Google 解决的是「事实检索」,那么 Engramme 要解决的则是「个人记忆」,二者根本不在同一个赛道。在架构层面,这也是一次全新的方向。
01记忆,自动找上门
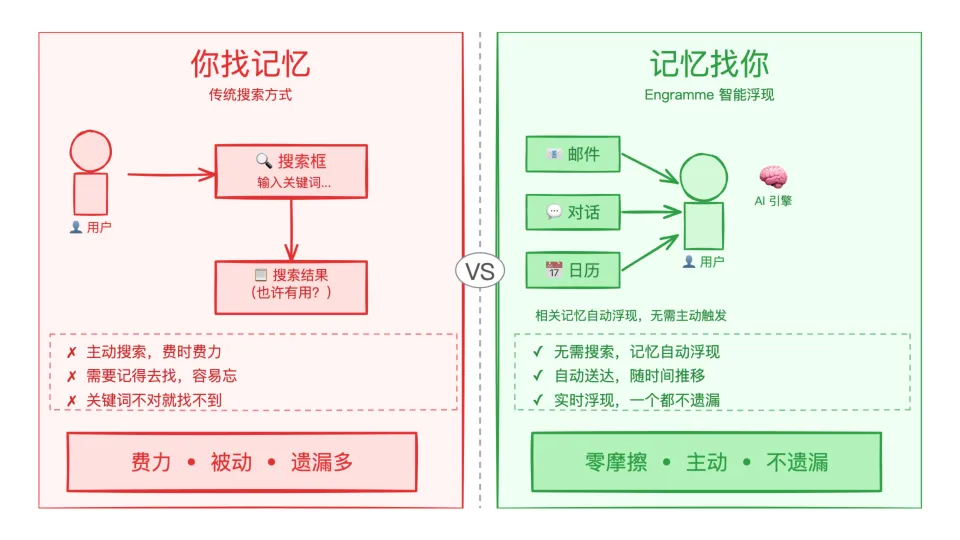
而 Engramme 的核心体验,则可以用三个场景来说明。


打开一封邮件,和对方相关的记忆自动浮现;加入一场视频会议,有用的背景信息在对话进行中送到你面前;发出一条消息,和这段关系有关的历史记录主动找到你。
不需要搜索,不需要提示。
这是 Kreiman 在发布帖子里重复了两次的一句话。
“ 你,就是你的记忆。记忆塑造了你。每一张脸,每一个地方,每一段对话……但人类的记忆是脆弱的。尽管我们与遗忘抗争了数千年,记忆仍在不断地从我们身边溜走。
视频的最后,用了三个短句收尾:
一场危机化于无形。一个判决得以改写。一条生命得以挽救。
这三个场景,已经不只是个人生产力工具的定位了。
记忆的暗物质
而 Kreiman 团队在推出产品之前,先做了一件事:搞清楚人类究竟需要记住什么。

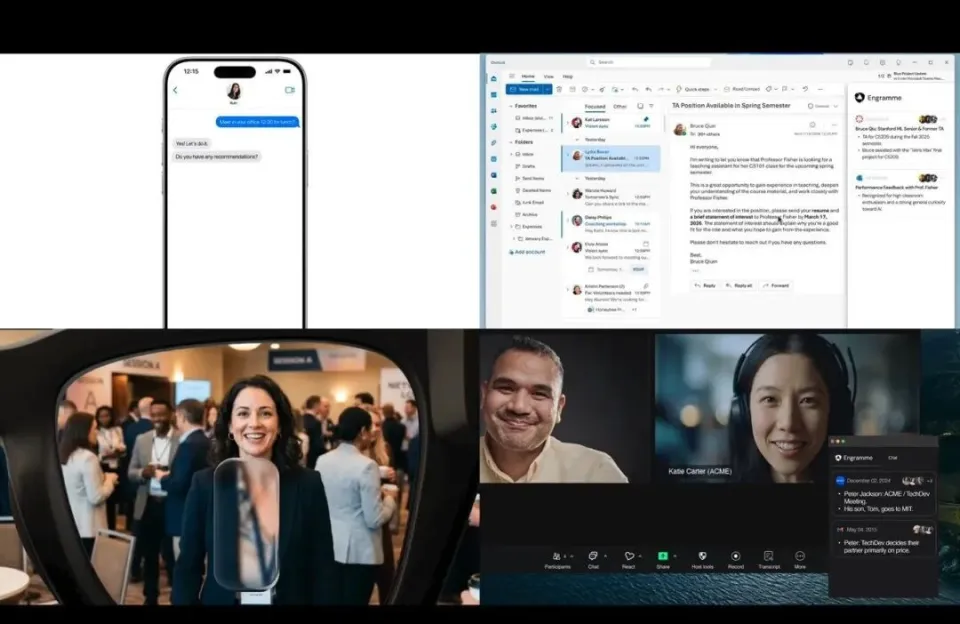
他们在 2026 年 3 月发布了一篇研究,招募了 134 名年龄在 18 到 80 岁之间的参与者,让他们在日常生活中记录所有「曾经知道、现在想不起来」的问题。
最终,他们收集到了 1,940 条有效的个人记忆问题。
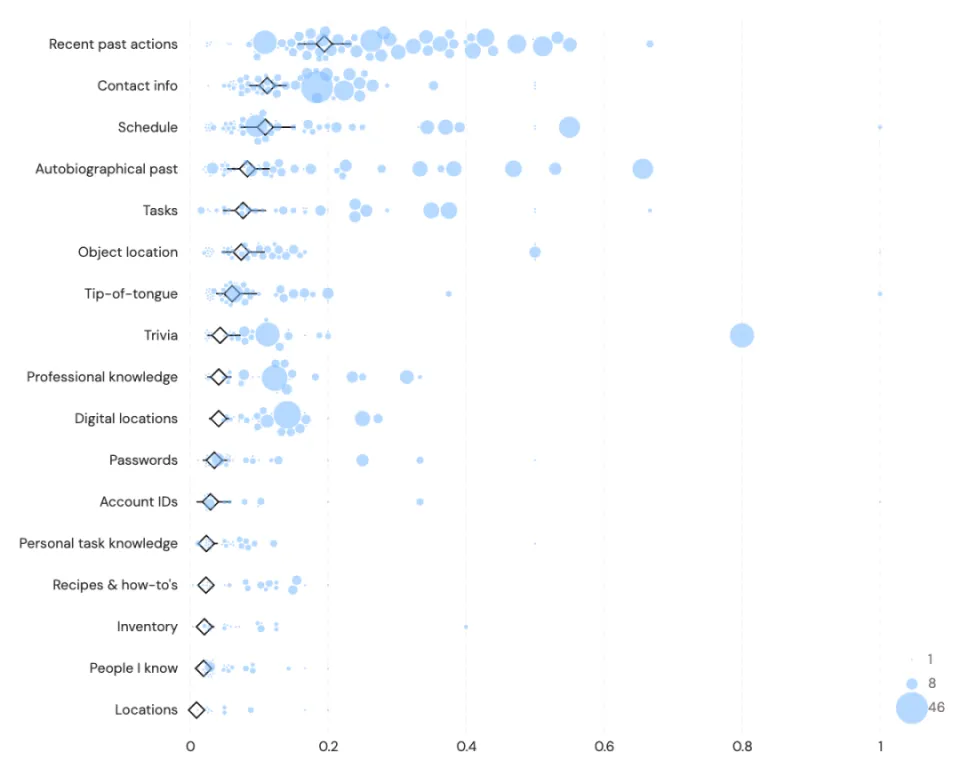
研究者把这些问题按 W 类型(What/When/Where/Who/How/Whether/Why)分类,结果中最显眼的是:「What」问题占了将近 40%。
人们最常遗忘的,是那种「那个叫什么来着」的问题,比「在哪里」「是谁」要高出一截。
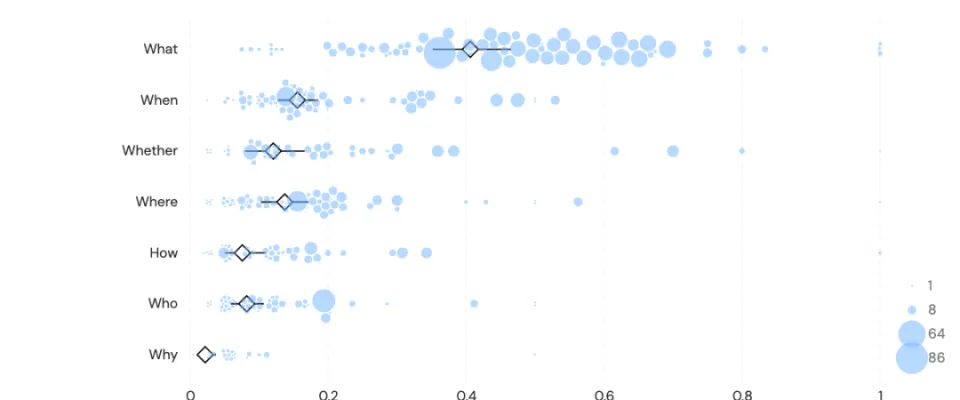
而在把问题拆得更细后,会发现一个反直觉的结论:人们最频繁想不起来的,是自己刚刚做过的事。
最常见的问题类型是「近期行为」,排在后面的依次是联系方式、日程安排、东西放哪了、待办事项、密码……
至于为什么「近期行为」会排第一呢?
研究者给出了两种解释:要么是近期记忆衰减得最快,要么是时间更久远的事早已彻底消失在「暗物质」里,连提问的机会都没有了。
这个概念就是他们提出的「记忆的暗物质」。
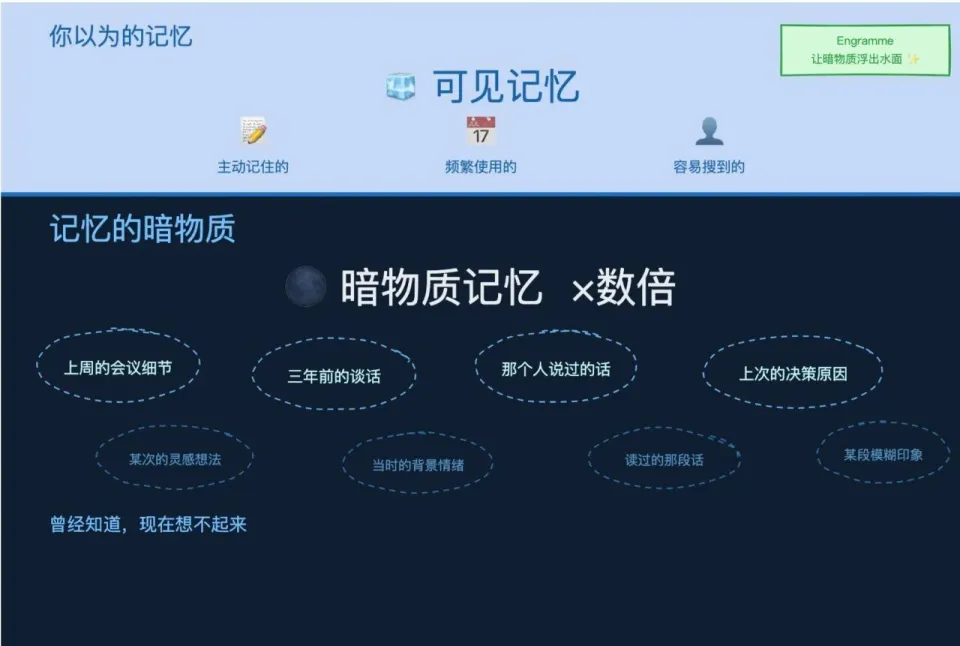
就像宇宙中的暗物质,规模庞大、无处不在,却极难直接触及。大多数个人记忆,都是你无法自由回想、但只要稍有线索就能认出的信息。
你以为忘了,其实只是被压进了深处。
研究还分析了不同活动场景下的记忆需求。「工作中」是触发记忆问题最多的场景,占 19.8%;「规划/整理」占 12.8%,「社交」占 11.0%。
而活动类型和记忆问题的匹配关系,有些出乎意料:
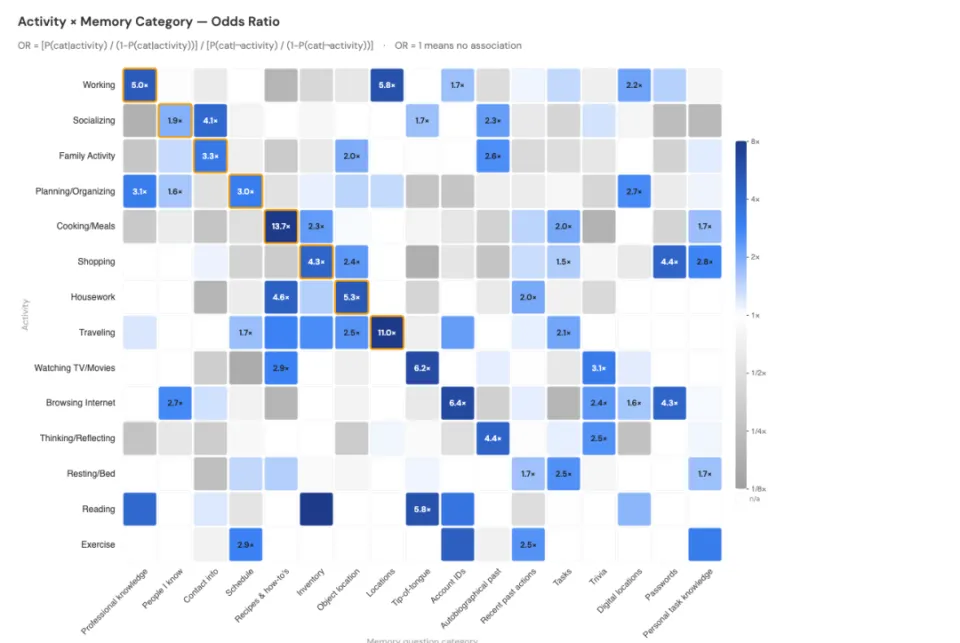
做饭时,想到配方问题的概率是平均水平的 13.7 倍。旅行时,想到位置问题的概率是平均水平的 11 倍。规划时,对日程的疑问也是平均水平的 3 倍。
这些数字,也说明了一件事:记忆需求是有强烈情境性的,而不是均匀分布在时间里的。
而 Engramme 要做的,正是在正确的情境下送来正确的记忆。
03Large Memory Models
Kreiman 在发布时提到,Engramme 构建了全新的 Large Memory Models(大记忆模型),专门用来解决遗忘问题。
这个命名是有意为之的,和 Large Language Models 形成呼应,但做的是完全不同的事。
产品连接的是用户的「memorome」,也就是整个数字生活的总和:邮件、通话、会议、消息、日程……所有这些沉淀下来的信息,都成为系统可以调用的记忆基底。
现有的 AI 工具,包括绝大多数 RAG(检索增强生成)系统,本质上都在做「搜索」,你查它才给。Engramme 要做的是反过来:系统主动判断「现在什么信息对你有用」,然后推送过来。
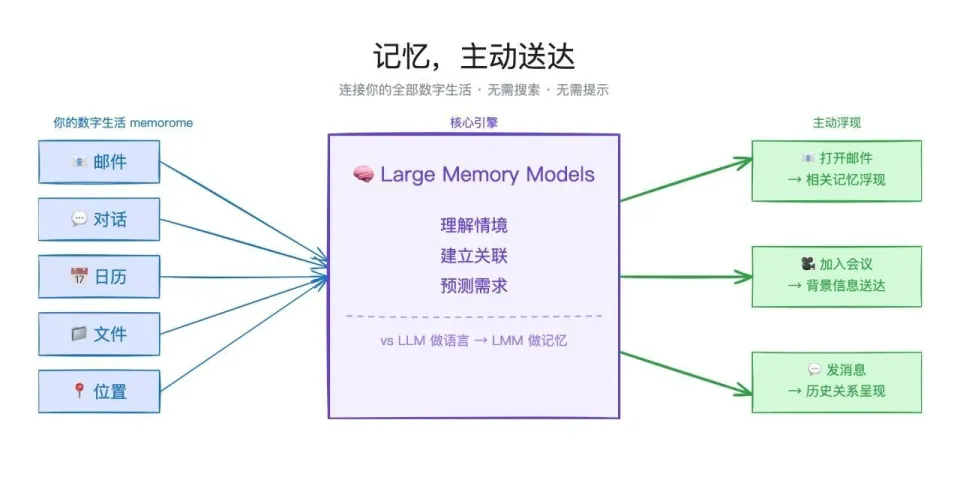
不是你问记忆,是记忆来找你。
这在技术实现上要比「搜索」难得多,因为它需要模型理解当前情境的语义,并在没有明确请求的情况下判断相关性。
04十年研究的壁垒
Engramme 的研究积累,是他们和其他做「AI 记录工具」的产品最根本的区别。
本站的新闻页面文章、图片、音频、视频等稿件均为自媒体人、第三方机构发布或转载。
如稿件涉及版权等问题,请与我们联系删除或处理,稿件内容仅为传递更多信息之目的,并不代表认同其内容数据或观点的真实性。


热门文章
最新文章

